
The Web Is Going Dark: What Happens to Google’s AI When Content Hides?
AI doesn’t create, it consumes. What happens next? Watch your email closely!

Thanks to this week's #SEOForLunch Sponsor: North Star InboundMy overly simple brain can’t stop wondering where all this AI/LLM magic leads us.
In the short term, it thrives without a single doubt. The momentum is real, and the technology is impressive.
But 5 to 10 years from now? What larger impact will this all have?
Hear me out... It could get ugly.
But let’s hope i’m dead ass wrong.
This week’s #SEOForLunch is sponsored by North Star Inbound.
Turn Your Blog Into Your Biggest Sales Engine
Brought to you by North Star Inbound–the sales enablement SEO agency.
How? Focus on high-impact SEO strategies that target the most profitable opportunities.North Star Inbound has a proven track record of creating top-converting blog pages that deliver
thousands of leads,
hundreds of thousands in directly-attributed revenue,
and rapid payback periods on SEO spend.
They focus on the 10% of pages with the highest ROI for your brand. Basically, your content becomes your most effective sales tool.
There’s no better way to loosen tight budgets than to grow revenue quickly.
Intrigued?

No Reward = No Public Content
We all know what’s happening:
Google, ChatGPT, Perplexity, Gemini…they’re crawling the open web like an all-you-can-eat buffet. Every scrap of content they can index, they do.
That data then gets served back to users as AI Overviews or LLM answers. No clicks, very little (or no) citations, just the output. And if we’re being generous, let’s simply assume the info is accurate. 🫢
But the publisher? They get nothing.
No visit. No brand exposure. No ROI. Just stuck footing the bill.
So what happens when creators get tired of feeding the beast for free?
Some say they will completely stop creating. I 100% disagree, but I bet you my last dollar they will take it private!
Newsletters. Slack groups. Discord channels. Paywalled content. Members-only communities.
The internet won’t die. It will simply hide.
Do AI/LLMs Risk Becoming Stale?
Let’s dig a little deeper into my thinking...
If Google and LLMs continue to discourage the creation of freely accessible content, what happens to the system that feeds them?
Less public content means less to crawl.
Less to crawl means less to learn from.
And less to learn from? That’s how they get old/stale (and forgotten!)
It’s not hard to imagine a future where AI Overviews and LLM responses rely on outdated, recycled, or regurgitated data. This isn’t because the models are bad, but because the web went quiet.
I suspect we’re already seeing the early signs.
Answers feel safer, more generic, and more meh. When fewer people share new thinking in public, the machines can’t learn. #googenough.
So what happens next? Where does the data come from when the web goes dark?
Well... that’s where things get uncomfortable.
Will Google Nuke Privacy Rights?
This is my “I f**ing hope not” scenario, but the logic is hard to ignore.
If the public web goes dark and content is locked behind paywalls and private groups, something else will have to fill the gap.
Enter: email.
Gmail alone holds 22% of the global email client market. That’s roughly 1.8 billion users.

So again, wrapping the tin foil really tight against my head right now…
1. Could OpenAI develop a partnership with Apple?
Or hell, would they consider buying Yahoo? It is 3% of market share.
2. Would Microsoft tap into Outlook usage to quietly train Copilot or boost Bing’s LLM accuracy?
Imagine a world where Bing answers are better than Google’s because Outlook had the training edge.
3. Or would… no, they wouldn’t… would they? Does Google just help itself?
It already owns 30% of the email market with Gmail. What stops it from using that content to train Gemini?
Let’s be honest. #3 just seems obvious.
Out of all the scenarios, Google turning Gmail into its next training set feels the most real. It doesn’t need permission. Just a TOS tweak and a press release full of updates focusing on “personalization improvements.”
Did You Know Google Already “Scans” Your Emails Automatically?
Ironically, I leveraged ChatGPT to summarize Google’s terms of service and Gmail policy. It found a few gems worth sharing.
Here’s the first one, straight from Google’s TOS:
"This includes using automated systems and algorithms to analyze your content: for spam, malware, and illegal content... to customize our services for you, such as providing recommendations and personalized search results, content, and ads."
That’s not just email delivery, that’s algorithmic parsing and behavioral tailoring.
Oh, and it gets better. Buried deeper in the TOS:
"You provide Google with permission to host, reproduce, distribute... and analyze your content… for the limited purpose of operating and improving the services."
Let’s just say we’ll revisit “improving the services” shortly.
ChatGPT produced this summary table of what Google can and can’t do to simplify things. This is based entirely on their public-facing policies as of March 21, 2025:
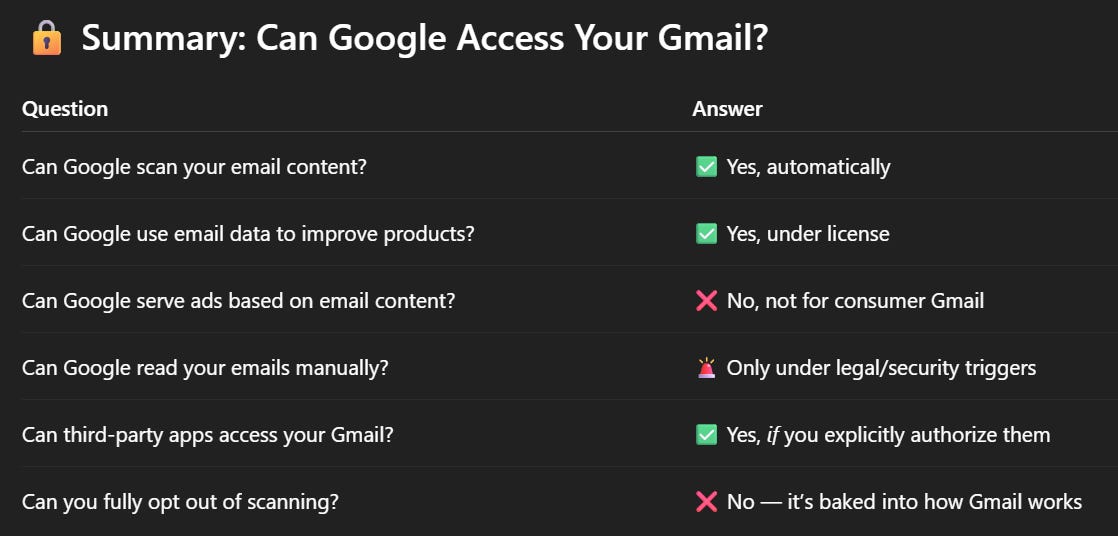
So technically, under their current TOS, Google isn’t using your Gmail content to train Gemini or power AI Overviews... YET.
But the system is already reading everything. All it takes is a change in what “improve the service” means in the bolded terms above, and the switch will flip.
Can Google Legally Change Its TOS?
Yes/No/Kinda.. By agreeing to Google’s Terms of Service, you already accept two clauses that make this whole scenario possible:
“...developing new technologies and services for Google consistent with these terms.”
+
“If we materially change these terms... We’ll provide you with reasonable advance notice and the opportunity to review the changes.”
Translation? Google can absolutely update the TOS to allow Gmail content to be used for LLM training. All they need to do is claim it fits under the umbrella of “improving services” or “developing new technologies.”
The only real hurdle? They have to alert you to the change of policy.
But let’s be honest, when was the last time you read a TOS update? Yeah, me neither.
One mass email. One blog post. A checkbox you clicked without thinking.
That’s all it takes for billions of inboxes to become AI fuel. Ugh, I’m gonna be sick!
No Way, Go Home Nick, You’re Drunk
At this point, the tin foil on my head is doing double duty, both amplifying the sun and slowly cooking my brain into a raisin.
But screw it, let’s push the boundaries just a bit further.
What if Google wants to stand by its old motto, “Don’t be evil” and stay “technically” compliant… and still pull this off?
(Also, fun fact: remember when they actually dropped that line from their code of conduct? Just saying.)
Here’s how they could do it. All hypothetically, of course:
Slip in a “Minor” TOS Edit
“We may use your content to improve Google services, including generative AI models, subject to applicable privacy controls.”Consent banner or “toggle” to opt out of LLM training
They could bury this option deep in its settings, with “opt in” being the default solution.Bake it into a new experiment/beta feature
Want to test Gmail’s latest feature? Excellent, just read (and agree) to these 5,000 words of legalese, handcrafted by the most expensive lawyers Google could pay.
It’s all “technically” opt-in and compliant. But functionally? It's simply default-on by design.
Gloves Off: Google Always Wins
This is the part where we admit the truth, and it stings. They’re playing a different game than the rest of us.
We’re out here defending the open web, and they’re rewriting the rules in the background. One experiment and product release at a time.
So yeah, maybe my tinfoil hat’s been on a little too tight. But also… just maybe the signs simply point to the future?
So Now What?
This isn’t about stopping Google. You won’t. I won’t. No one will. But it is about understanding the new publishing landscape:
If you create valuable content, you should think twice about giving it away for free. (Yeah, I get the irony as some of you are reading this on the open web right now. You can fix that by clicking that little subscribe button below!)
If you’re building a brand, don’t rely on Google to keep things humming.
Build in places where YOU control access, experience, and relationships. I’m not saying don’t leverage Google; simply don’t rely on it as the backbone of your business.If you're still trying to win Google's game, understand this: the rules aren’t just changing, they’re being rewritten in real time. The only constant with Google is that it never stops evolving.
The free web? It’s not dead. But it’s fading.
And AI may be the reason it never recovers.
That’s enough tinfoil for one week. Pretty sure it belongs on burritos, not my head anyway.
Next week, I’ll try to be a little less “robots are eating us” at the lunch table!
Like the direction of thought here, don’t think Gmail or any major email for that matter could be leveraged to train a public model, far too risky because of the nature of all the private and confidential information in there.
That said, what G and M are both doing is using it at the user level, which will continue to give them an edge. Google has your search history, your GPS, your browsing history, your app history (G apps) , among other things. Add emails to that list and that training dataset is hard to replicate for anyone else as a leverage for their LLM. The delta is too big to travel.
I agree here Nick. AI is moving so quickly that it's hard to look far down the road sometimes, but this fundamental shift is going to upend the future of the web. A decade ago, we had an unspoken agreement with Google that we would give them information in exchange for traffic, and now that agreement is null and void. Companies everywhere are going to find ways to protect their IP while still scouring for prospects.